Build an ML Pipeline for Short-term Rental Prices in NYC
Project Description | Install | Login to Wandb | Cookiecutter | Hydra | Pandas Profiling | Release new version | Step-by-step | Public Wandb project | Code Quality
Project Description
Working for a property management company renting rooms and properties for short periods of time on various platforms. Need to estimate the typical price for a given property based on the price of similar properties. Your company receives new data in bulk every week. The model needs to be retrained with the same cadence, necessitating an end-to-end pipeline that can be reused.
Source code: vnk8071/reproducible_model_workflow
tree projects/reproducible_model_workflow -I 'wandb|__pycache__'
projects/reproducible_model_workflow
├── MLproject
├── README.md
├── components
├── conda.yml
├── config.yaml
├── cookiecutter-mlflow-template
├── environment.yml
├── images
├── main.py
└── src
25 directories, 56 files
| # | Feature | Stack |
|---|---|---|
| 0 | Language | Python |
| 1 | Clean code principles | Autopep8, Pylint |
| 2 | Testing | Pytest |
| 3 | Logging | Logging |
| 4 | Configuration | Hydra |
| 5 | Visualize dataframe | Pandas Profiling |
| 6 | Pipeline & Monitoring | Mlflow |
| 7 | Experiment tracking | Weights & Biases |
Install
In order to run these components you need to have conda (Miniconda or Anaconda) and MLflow installed.
conda env create -f environment.yml
conda activate nyc_airbnb_dev
Login to Wandb
wandb login
Cookiecutter
Using this template you can quickly generate new steps to be used with MLFlow.
cookiecutter cookiecutter-mlflow-template -o src
step_name [step_name]: basic_cleaning
script_name [run.py]: run.py
job_type [my_step]: basic_cleaning
short_description [My step]: This steps cleans the data
long_description [An example of a step using MLflow and Weights & Biases]: Performs basic cleaning on the data and save the results in Weights & Biases
parameters [parameter1,parameter2]: parameter1,parameter2,parameter3
Hydra
As usual, the parameters controlling the pipeline are defined in the config.yaml file defined in the root of the starter kit. We will use Hydra to manage this configuration file. Open this file and get familiar with its content. Remember: this file is only read by the main.py script (i.e., the pipeline) and its content is available with the go function in main.py as the config dictionary. For example, the name of the project is contained in the project_name key under the main section in the configuration file. It can be accessed from the go function as config["main"]["project_name"].
Pandas Profiling
ydata-profiling primary goal is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Like pandas df.describe() function, that is so handy, ydata-profiling delivers an extended analysis of a DataFrame while allowing the data analysis to be exported in different formats such as html and json.
pip install ydata-profiling
profile = ProfileReport(df, title="Profiling Report")
profile.to_widgets()
Release new version
git tag -a 1.0.1 -m "Release 1.0.1"
git push origin 1.0.1
Step-by-step
0. Full pipeline
mlflow run .
1. Download data
mlflow run . -P steps=download
2. EDA
mlflow run src/eda
More details in Jupyter
3. Basic cleaning
mlflow run . -P steps=basic_cleaning
...
2023-08-20 22:17:49,537 Dropping duplicates
2023-08-20 22:17:49,566 Dropping outliers
2023-08-20 22:17:49,566 Number of rows before dropping outliers: 20000
2023-08-20 22:17:49,570 Number of rows after dropping outliers: 19001
2023-08-20 22:17:49,570 Converting last_review to datetime
2023-08-20 22:17:49,577 Saving cleaned dataframe to csv
2023-08-20 22:17:49,743 Logging artifact
4. Check data
mlflow run . -P steps=check_data
...
test_data.py::test_column_names PASSED [ 16%]
test_data.py::test_neighborhood_names PASSED [ 33%]
test_data.py::test_proper_boundaries PASSED [ 50%]
test_data.py::test_similar_neigh_distrib PASSED [ 66%]
test_data.py::test_price_range PASSED [ 83%]
test_data.py::test_row_count PASSED [100%]
5. Split data
mlflow run . -P steps=data_split
...
2023-08-21 19:13:21,935 Fetching artifact clean_sample.csv:latest
2023-08-21 19:13:25,410 Splitting trainval and test
2023-08-21 19:13:25,461 Uploading trainval_data.csv dataset
2023-08-21 19:13:31,353 Uploading test_data.csv dataset
6. Train and evaluate model
mlflow run . -P steps=train_random_forest
...
2023-08-21 19:55:39,523 Minimum price: 10, Maximum price: 350
2023-08-21 19:55:39,549 Preparing sklearn pipeline
2023-08-21 19:55:39,550 Fitting
2023-08-21 19:55:41,063 Computing and scoring r2 and MAE
2023-08-21 19:55:41,240 Score: 0.5519470714568394
2023-08-21 19:55:41,241 MAE: 34.12780800870754
2023-08-21 19:55:41,241 Exporting model
2023-08-21 19:55:41,242 Uploading model
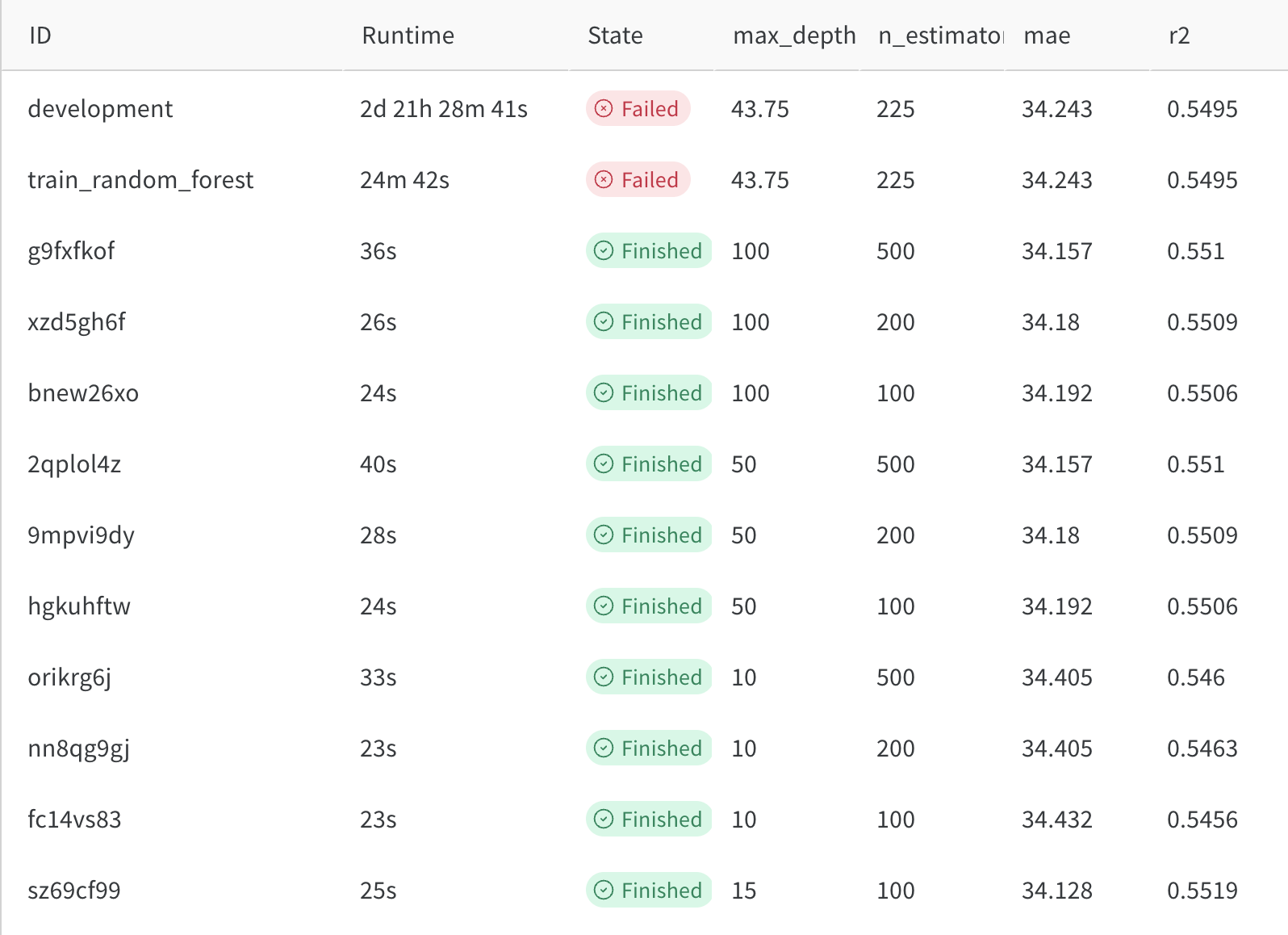
Optimize hyper-parameters
mlflow run . \
-P steps=train_random_forest \
-P hydra_options="modeling.random_forest.max_depth=10,50,100 modeling.random_forest.n_estimators=100,200,500 -m"
7. Test model
mlflow run . -P steps=test_regression_model
...
2023-08-21 20:52:23,425 Downloading artifacts
2023-08-21 20:52:29,760 Loading model and performing inference on test set
2023-08-21 20:52:32,254 Scoring
2023-08-21 20:52:32,341 Score: 0.5640242000942114
2023-08-21 20:52:32,341 MAE: 33.850181065122136
8. Test model with new dataset
mlflow run https://github.com/vnk8071/ml-production.git -v 1.0.1 -P hydra_options="etl.sample='sample2.csv'"
...
2023-08-21 22:06:44,481 Dropping duplicates
2023-08-21 22:06:44,607 Dropping outliers
2023-08-21 22:06:44,607 Number of rows before dropping outliers: 48895
2023-08-21 22:06:44,630 Number of rows after dropping outliers: 46427
2023-08-21 22:06:44,631 Converting last_review to datetime
2023-08-21 22:06:44,654 Saving cleaned dataframe to csv
2023-08-21 22:06:45,052 Logging artifact
...
test_data.py::test_column_names PASSED [ 16%]
test_data.py::test_neighborhood_names PASSED [ 33%]
test_data.py::test_proper_boundaries PASSED [ 50%]
test_data.py::test_similar_neigh_distrib PASSED [ 66%]
test_data.py::test_price_range PASSED [ 83%]
test_data.py::test_row_count PASSED [100%]
...
2023-08-21 22:09:01,322 Downloading artifacts
2023-08-21 22:09:04,782 Loading model and performing inference on test set
2023-08-21 22:09:05,168 Scoring
2023-08-21 22:09:05,298 Score: 0.6195968265496492
2023-08-21 22:09:05,298 MAE: 31.64257699859779
Public Wandb project
Link: https://wandb.ai/nguyenkhoi8071/nyc_airbnb/overview?workspace=user-nguyenkhoi8071
Select best model

Code Quality
Style Guide - Format your refactored code using PEP 8 – Style Guide. Running the command below can assist with formatting. To assist with meeting pep 8 guidelines, use autopep8 via the command line commands below:
autopep8 --in-place --aggressive --aggressive .
Style Checking and Error Spotting - Use Pylint for the code analysis looking for programming errors, and scope for further refactoring. You should check the pylint score using the command below.
pylint -rn -sn .
Docstring - All functions and files should have document strings that correctly identifies the inputs, outputs, and purpose of the function. All files have a document string that identifies the purpose of the file, the author, and the date the file was created.